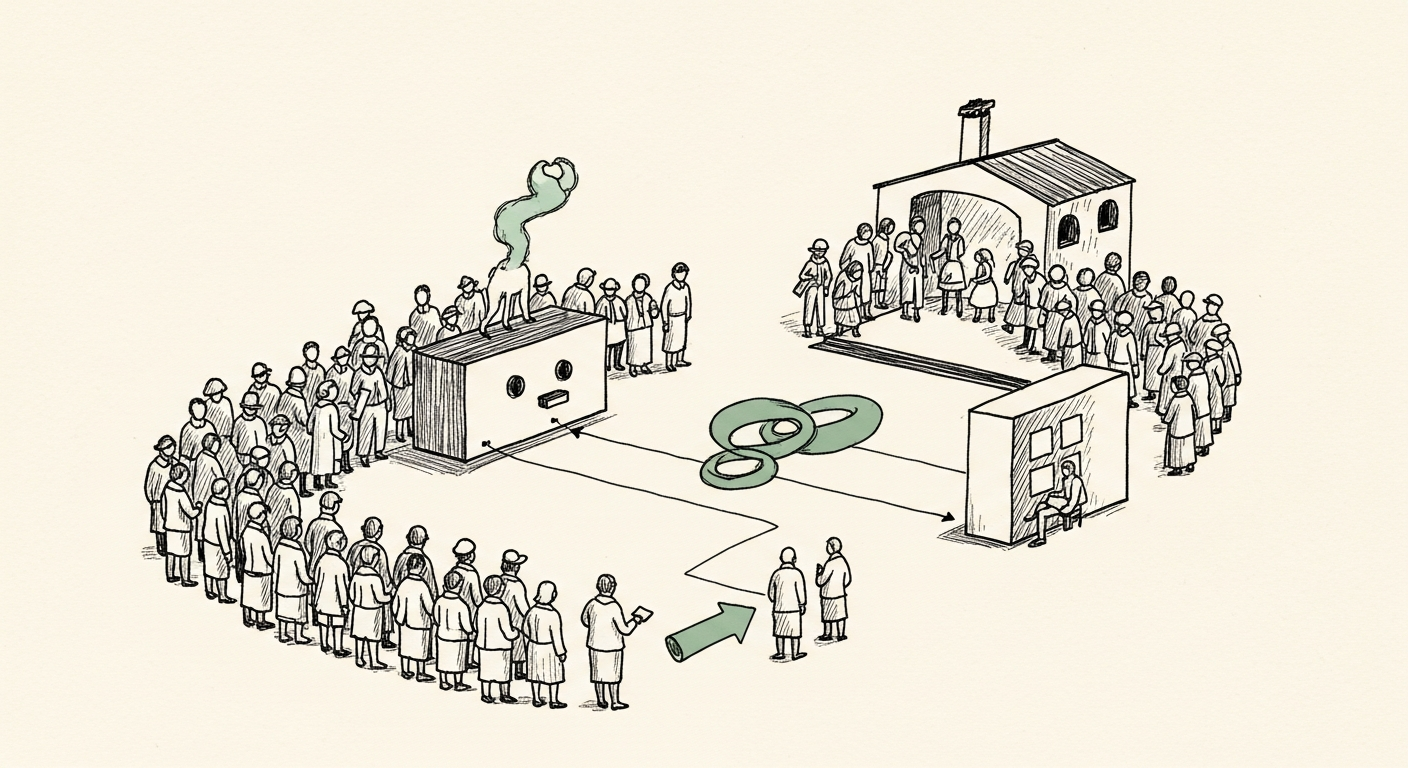
What happened
OpenAI published a guide on building self-improving AI agents for specialised domains. The post details a system using their Codex model to tackle complex tax questions — a task requiring high accuracy. The agent works by generating answers, getting feedback on their correctness, and then adding verified examples to its context to improve future performance.
This demonstration, detailed in their official post, is presented as a blueprint for automating enterprise workflows where correctness is critical and can be programmatically verified.
How the room's reading it
The agent-building community sees this as a strong signal for how to move beyond simple chatbots. Builders focused on enterprise automation are analysing the pattern — a tight loop of generation, verification, and learning — as a viable way to handle complex, rule-based domains. The core idea of using a model to bootstrap its own training data is landing well with teams who find traditional fine-tuning too slow or expensive.
Scepticism is focused on the term 'self-improving'. Some developers on X point out it's more of a sophisticated, automated feedback loop than true autonomous learning. The consensus is that while it's not AGI, it’s a practical and powerful technique for specific problems.
Sailfish's take
We see this as less about tax code and more about a repeatable recipe for quality. The key insight isn't the model — it's the feedback loop. We've shipped systems with similar loops for data cleaning and classification, and they work reliably when the definition of 'correct' is sharp and verifiable.
The real product here is the pattern: generate, verify, and cache. This approach turns a probabilistic model into a more deterministic system over time, which is exactly what enterprise clients need. We think this blueprint is ready for production in any domain with structured rules — think legal document analysis, insurance claim validation, or internal compliance checks. It's a solid template for building trust in AI outputs.